| |
Лекция 1_02: Наборы из нулей и единиц
Общие замечания
В этой лекции мы рассматриваем элементы множества Bk
— наборы фиксированной длины из нулей и единиц. Такие наборы можно трактовать по-разному,
часто полезно сопоставлять эти трактовки и быстро в случае надобности переходить от одной
к другой.
|
Трактовки наборов из k нулей и единиц
- Вершина куба.
- Характеристический вектор множества.
- Набор булевых значений.
- Картинка.
- Двоичное представление целого числа.
- Состояние памяти компьютера.
- Символ кодировки.
- Путь в целочисленной решетке.
- Результаты случайных испытаний (например, бросаний монеты).
- И другие, более сложные.
|
Вершина куба
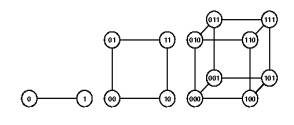 Начнем с того, что набор из
Начнем с того, что набор из k нулей и единиц можно
трактовать как вершину
k –мерного единичного куба, у которого одна из вершин
находится в начале координат, а исходящие из нее ребра лежат на координатных осях.
Такой куб легко представить себе для k , равного 1, 2
и 3, а для больших размерностей все «выглядит аналогично». Попробуйте!
|
Вот интересное использование этой трактовки 0-1-наборов.
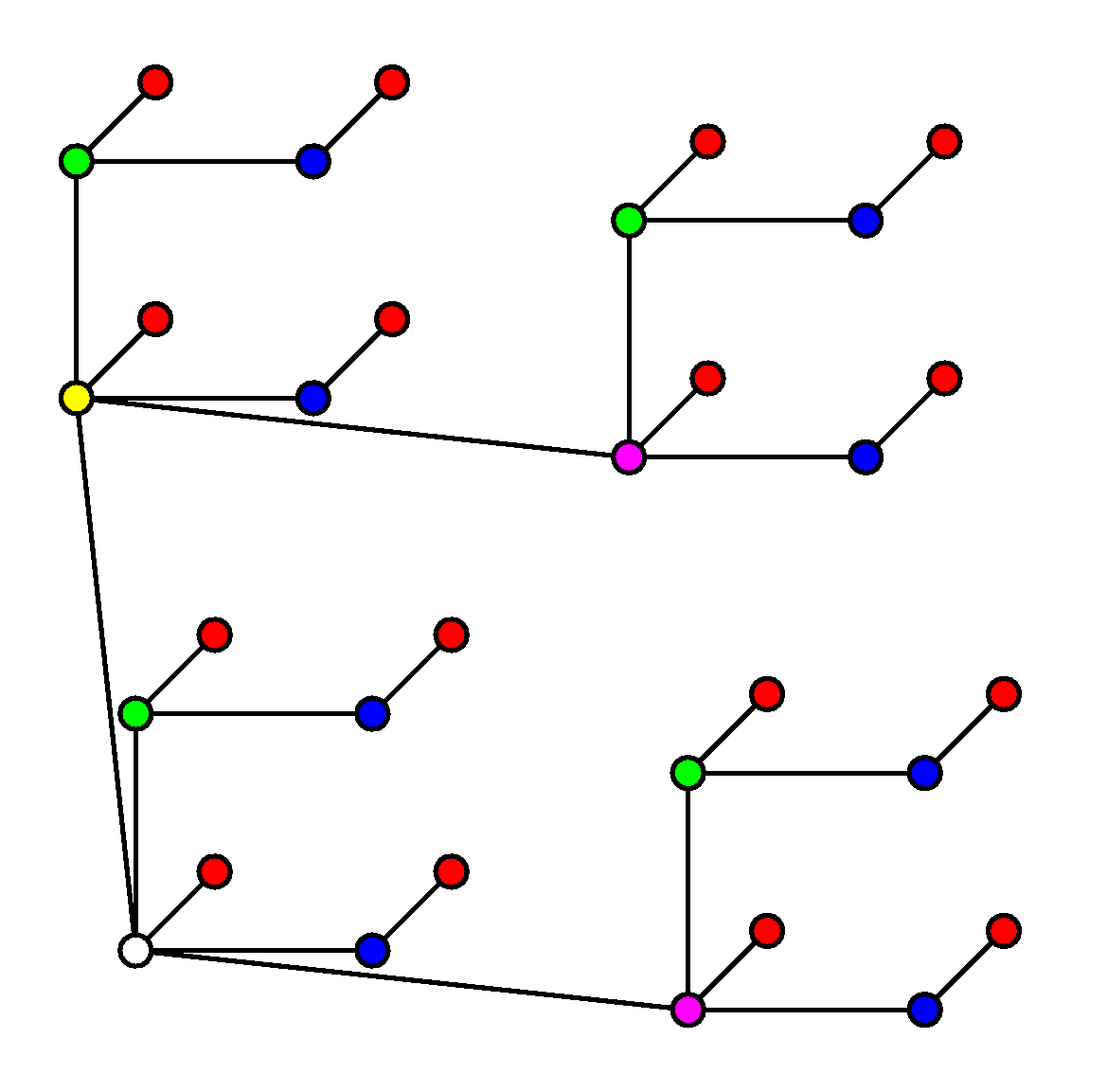 Изобразим 5-мерный куб, в котором проведены только ребра, необходимые для минимальной
связи между вершинами.
Изобразим 5-мерный куб, в котором проведены только ребра, необходимые для минимальной
связи между вершинами.
Так устроено соединение процессоров во многопроцессорных компьютерах.
В них обычно вершин-процессоров больше, типично k=16 .
Но все, что нужно, мы увидим здесь.
Каждый процессор кодируется набором из пяти 0-1 символов. Процессор, в коде которого
последний символ 1, связывается с процессором, у которого код отличается только
в последнем символе — там стоит 0. Например, процессор 10111 прицепляется к 10110.
Процессор, код которого оканчивается на 10, прицепляется к процессору с кодом,
отличающимся во втором с конца символе: так что 10110 связывается с 10100. И т. д.
Это близкие соединения. По ним соединяются любые два процессора.
|
Упражнение
Постройте в 10-мерном кубе путь от процессора 0110100110 к процессору
0111110011 .
|
Набор булевых значений
 Что такое булевы значения?
Что такое булевы значения?
Английский математик Джордж Буль (1815-1864) в 1854 году предложил систему исчисления логических
высказываний, введя новый тип логических величин, принимающих два значения —
ИСТИНА и ЛОЖЬ (True и False ).
Для этих (булевых) величин были введены своеобразные операции, вполне естественные
с точки зрения формальной логики.
Сейчас булевы величины широко используются в программировании (тип Boolean ).
Мы сейчас рассмотрим булевы величины, операции с ними и их связь с 0-1 значениями.
|
Булевы значения и операции
Начнем с примеров булевых значений.
“π > 3.1415926” — это ИСТИНА ,
“π > 4.0005926” — это ЛОЖЬ ,
“x > y+3” — это ИСТИНА или ЛОЖЬ ,
в зависимости от значений x и
y .
Операция отрицание , она же НЕТ или NOT
или Ø ( ! в языке программирования Си) имеет
один логический операнд (она одноместная )
и вырабатывает противоположное ему значение:
Ø True = False
Ø False = True
Ø (π > 3.1415926) = False
|
Операция конъюнкция
Эта операция называется еще логическим умножением или логическим
И и обозначается AND ,
а также
Ù
или & .
У нее два булевских операнда и результат операции также булевское значение
«оба операнда истинны» .
Например, (x > 3) Ù (x < 7)
истинно для всех x , которые больше 3 и меньше 7.
|
Операция дизъюнкция
Эта операция называется еще логическим сложением или логическим
ИЛИ и обозначается OR , а также
Ú или || .
У нее два булевских операнда и результат операции также булевское значение
«хотя бы один из операндов истинен» .
Например, (x > 7) Ú (x < 3)
истинно для всех x , которые больше 7, и всех, которые
меньше 3.
|
Операция эквиваленция
Часто эту операцию называют эквивалентностью . Ее обозначают EQU
или º .
У нее два булевских операнда и результат операции также булевское значение
«значения операндов одинаковы» .
Например,
(x > 7) º (x > 3)
истинно для всех x , которые больше 7, и всех, которые меньше 3.
|
Операция «исключающее ИЛИ»
Эта операция обозначается XOR
(от eX clusive OR ),
она общепринятого обозначения не имеет, хотя в одной очень авторитетной системе я видел
подчеркнутый знак Ú : Ú .
У этой операции два булевских операнда, и ее результат также булевское значение:
«значения операндов не совпадают» .
(x > 3) XOR (x < 7) истинно для всех
x , которые меньше 3, и для всех,
которые больше 7.
Эта операция имеет удобное свойство
(a Ú b)
Ú b = a ,
которое используется в компьютерной графике (например, для изображения быстро перемещаемого знака).
|
Операция импликация
Редко используемая операция «следования» обозначается IMP
(от IMP lication ), или É .
У нее два булевских операнда и результат операции также булевское значение
«либо ложен первый операнд, либо истинен второй» .
(x < 3) IMP (x < 7) истинно для всех
x , которые больше 3 и меньше 7.
|
Таблица логических операций
|
|
x Ù y |
x Ú y |
x º y |
x Ú y |
x É y |
|
|
|
F |
F |
T |
F |
T |
F |
T |
F |
T |
F |
F |
T |
F |
T |
T |
T |
T |
T |
F |
T |
|
|
0-1 представление булевых значений
Естественна трактовка единицы и нуля как логических значений, соответственно,
как True и False .
Все логические операции легко переписать для этого представления.
Но и 0-1 набор можно представлять как набор логических значений и все перечисленные
логические операции выполнять над наборами-операндами покомпонентно .
|
Пример логических операций над 0-1 наборами
|
|
0000000 11111111 |
000 1111 000 11111 |
|
x Ù y |
x Ú y |
x º y |
x Ú y |
x É y |
|
0000000000 11111 |
000 111111111111 |
111 0000000 11111 |
000 1111111 00000 |
1111111 000 11111 |
|
|
Логические функции
Комбинируя значения отдельных компонент логического набора в более сложных операциях,
можно составлять более сложные функции от логических аргументов.
Функция от логических значений, принимающая логические значения, называется
логической функцией .
Заметим, что каждая логическая функция может быть задана таблицей истинности
— перечислением тех наборов аргументов, которым соответствует значение True .
Используя эту таблицу, всегда можно представить логическую функцию в виде дизъюнкции конъюнкций:
f(x1,x2,…,xk) =
Ú a ∈ T
(Ù i ∈ 1:k
v(xi,a) ),
где T — таблица истинности. Каждый входящий
в нее набор a определяет для каждой переменной
xi
способ ее вхождения в дизъюнкцию, соответствующую a :
входит в нее сама переменная или ее отрицание. Эта зависимость спрятана
в функции a . Такая функция называется
дизъюнктивной нормальной формой ,
или сокращенно ДНФ
Интересна задача сокращения записи ДНФ до минимума.
|
Характеристический вектор множества
Если сопоставить элементы конечного множества S
мощности k позициям в наборе из
k нулей и единиц,
то подмножествам можно сопоставить такие наборы.
Пусть для простоты S = 1:9 . Подмножеству
A = {1,2,6,7,9}
соответствует набор 110001101 .
Такой 0-1 набор c A
называется характеристическим вектором
множества S .
Операции над множествами легко моделируются логическими операциями над их
характеристическими векторами.
Например,
c A З B =
c A Ù c B
.
(Греческая буква c
называется хи .
Если вы не помните наизусть греческих букв, то можете воспользоваться нашим
справочником.)
|
Двоичное представление числа
Вы, конечно, знаете, что каждое натуральное число однозначно представимо в виде
суммы степеней 2, причем каждая степень в этой сумме появляется не больше одного раза,
т. е. с коэффициентом 0 или 1. Эти коэффициенты составляют представление
числа в двоичной системе счисления .
Например, 83 = 64+16+2+1 = 1010011.
Таким образом, каждый набор из k нулей и единиц
соответствует какому-либо числу в диапазоне от 0 до
2k−1 .
Из нахождения двоичного представления не нужно устраивать великого мероприятия. Нужно
просто записать нужное число, а рядом остаток от его деления на два. Затем под числом
записать частное от этого деления и повторять этот процесс пока частное не будет равно
нулю. Остатки от деления, прочитанные снизу вверх, и дадут искомое представление. Вот так:
|
37965 1
18982 0
9491 1
4745 1
2372 0
1186 0
593 1
296 0
148 0
74 0
37 1
18 0
9 1
4 0
2 0
1 1
|
Итак 3796510 = 10010100010011012 .
|
Степени двойки
Степени двойки из-за использования двоичной системы встречаются так часто,
что некоторые из них полезно помнить наизусть.
Число 210 — это наша тысяча. Оно
обозначается K и называется кило , (ср. килобайт).
220 = 1 048 576 — это миллион
(мега, M ).
Дальше следуют гига, G, и тера, T ,
найдите их значения сами.
А когда найдете, можете сравнить со значениями в нашем справочнике
|
Арифметические действия с двоичными числами
Вы, конечно, знаете, как удобно выполнять арифметические действия с двоичными числами.
Напомним, начиная с самого простого, с прибавления единицы.
Как прибавить единицу к числу 10001110100011111 ?
Ответ: двигаясь от конца к началу, заменять единицы на нули, а встретив нуль,
заменить его на единицу и остановиться.
В рассматриваемом случае получится 10001110100100000 .
Красным выделена изменившаяся часть.
Разработано много эффективных схем сложения, вычитания, умножения и деления двоичных чисел.
Мы ими заниматься не будем.
Но нужно упомянуть об особом случае умножения и деления двоичного числа на степень двойки
2k .
Умножение выполняется приписыванием к записи числа k нулей.
В компьютере это соответствует сдвигу записи числа на
k позиций влево. Существуют машинные команды сдвига.
Мы говорим влево , считая, что число записано в компьютере так, как мы
привыкли писать на бумаге — младшие разряды правее левых. В некоторых случаях
полезно считать, что запись идет в противоположном направлении. К этому вопросу мы еще
вернемся.
А про команды сдвига нужно поговорить еще.
Ясно, что сдвиге влево старшие разряды теряются (а при делении — сдвиг происходит
вправо , и теряются младшие разряды). Существуют команды циклического
сдвига, в которых вытесняемые разряды занимают освобождающиеся места с другого конца
записи. Например, циклический сдвиг на три разряда влево выглядит так (показаны номера
разрядов)
12345678 ® 45678123 .
Как написать программу циклического сдвига элементов массива, не использующую большой
дополнительной
памяти (порядка длины массива)? Вот неожиданное решение:
procedure mirror(l,r: integer);
begin
while l < r do begin
swap(a[l],a[r]);
Inc(l); Dec(r);
end;
end;
mirror(1,n); mirror(1,k); mirror(k+1,n);
Здесь используется простенькая процедура swap , меняющая местами два значения.
С ее помощью пишется процедура mirror , переворачивающая часть массива.
используя эту процедуру, мы весь массив перевернули, а потом отдельно перевернули
начало и конец.
|
Более удобные системы счисления
Двоичная система счисления удобна для компьютера, но неудобна для человека
— слишком длинные получаются записи чисел:
010101110001011101011010
Даже длину такой записи трудно определить!
Компромиссом между интересами человека и машины являются системы счисления с основаниями,
близкими к 10, но являющимися степенью двойки — 8 и 16.
В восьмеричной системе , совершенно естественно, 8 цифр — 0, 1, 2, 3, 4, 5, 6, 7.
Каждому разряду восьмиричной системы соответствуют 3 разряда двоичной системы,
и переход от одной системы к другой очень прост:
0 — 000 2 — 010 4 — 100 6 — 110
1 — 001 3 — 011 5 — 101 7 — 111
Число из предыдущего абзаца в этой системе записывается так:
| 010 |
101 |
110 |
001 |
011 |
101 |
011 |
010 |
| 2 |
5 |
6 |
1 |
3 |
5 |
3 |
2 |
Итак, 25613532.
Восьмеричная запись сейчас используется относительно редко.
Шестнадцатеричная система , напротив, очень популярна.
В ней 16 цифр.
Десять обычных — 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. Еще шесть — это буквы A, B, C, D, E, F.
Каждому разряду соответствуют 4 разряда двоичной системы:
0 — 0000 4 — 0100 8 — 1000 C — 1100
1 — 0001 5 — 0101 9 — 1001 D — 1101
2 — 0010 6 — 0110 A — 1010 E — 1110
3 — 0011 7 — 0111 B — 1011 F — 1111
Число из примера в этой системе записывается так:
| 0101 |
0111 |
0001 |
0111 |
0101 |
1010 |
| 5 |
7 |
1 |
7 |
5 |
A |
Итак, 57175A.
Особенно широко используется 16-ричная запись при обсуждении вопросов памяти компьютера.
|
Память компьютера
Вся память компьютера состоит из мельчайших магнитных элементов, каждый из
которых может находиться в одном из двух состояний. Одно из них отождествляется
с нулем, а другое с единицей. Машина может «прочесть» состояние магнита, а,
значит, и хранимую им двоичную цифру. Такая цифра называется битом (bit).
Так как этих цифр очень много, то с ними невозможно работать без укрупнения.
Первое укрупнение — это объединение битов в восьмерки — байты (byte).
Байт — минимальная адресуемая единица памяти.
Это значит, что машинная команда, работающая с памятью может добраться только
до всего байта целиком или до еще более крупной единицы памяти. Выделять
в байте отдельные биты нужно специальными дополнительными действиями.
Пара подряд идущих байтов называется машинным словом (word).
Слово располагается так, чтобы минимальный из адресов байтов был четным (это
называется выравниванием — слово выравнивается на четный адрес).
Один из байтов старший, а другой младший.
Где расположен младший байт? В разных компьютерах по-разному. Если впереди,
то говорят, что компьютер мелкоконечный (Little-Endian
— этот термин ввел Джонатан Свифт в «Путешествии Гулливера»).
Если сзади, то компьютер крупноконечный (Big-Endian ).
Наши персональные компьютеры — мелкоконечные, и когда вы находите в памяти
целое число, занимающее два байта, например, 515 = 020316 ,
то в первом байте пишется 03 , а во втором — 02 .
|
Побайтовое кодирование символов
Важным событием в развитии информатики (Computer Science) и вычислительной техники
было принятие байта в качестве единицы при кодировании символов. Вначале такие коды были
приняты фирмой IBM при разработке знаменитого комплекса IBM-360, а сейчас превратились
в общемировой стандарт.
В Советском Союзе внедрением машин Единой Серии (ЕС), клонировавших IBM-360, байты
появились «автоматически». Было очень удобно, что в
256 = 28 кодовых возможностей
свободно умещаются и прописные и строчные буквы и латиницы и кириллицы.
|
Стандарты кодирования. Стандарт ASCII
Сейчас самым важным стандартом (их несколько) является ASCII .
Это аббревиатура для A merican S tandard
C ode for I nformation I nterchange
.
Он стал мировым стандартом кодировки для практически всех компьютеров. В этом коде
на каждый символ приходится по одному байту, причем стандарт фиксирует верхнюю
половину таблицы с кодами от 0 до 127 .
Представив байт двумя 16-ричными цифрами, мы можем сказать, что это коды от 00
до 7F . Некоторые сведения об этой таблице хорошо запомнить.
Первые две строчки заполнены служебными символами (типа возврата каретки, перевода
строки, табуляции, звонка, конца передачи).
Следующая строка начинается с 20 — кода пробела. Дальше идут
различные специальные знаки, которые можно не помнить.
Дальше идет строка цифр: от 30 для 0 до 39 для 9.
Остаток заполнен спецзнаками.
Строки 4 и 5 заполнены прописными латинскими буквами: 40 для
@
(at «коммерческое» , а совсем не собака ),
41 для A и т.д. вплоть до 5A для Z .
Строки 6 и 7 аналогично заполнены строчными латинскими буквами.
60 используется для ` (обратного апострофа).
| |
0 | 1 | 2 | 3 |
4 | 5 | 6 | 7 |
8 | 9 | A | B |
C | D | E | F |
| 0 |
| | | |
| | | |
| | | |
| | | |
| 1 |
| | | |
| | | |
| | | |
| | | |
| 2 |
sp | | | |
| | | |
| | | |
| | | |
| 3 |
0 | 1 | 2 | 3 |
4 | 5 | 6 | 7 |
8 | 9 | | |
| | | |
| 4 |
@ | A | B | C |
D | E | F | G |
H | I | J | K |
L | M | N | O |
| 5 |
P | Q | R | S |
T | U | V | W |
X | Y | Z | |
| | | |
| 6 |
` | a | b | c |
d | e | f | g |
h | i | j | k |
l | m | n | o |
| 7 |
p | q | r | s |
t | u | v | w |
x | y | z | |
| | | |
Почти полную таблицу (без объяснения части служебных кодов) можно найти, например,
в нашем справочнике.
Вторая половина таблицы ASCII существует в нескольких вариантах (они называются
codepages — кодовые страницы).
Для нас наиболее важны следующие страницы
- 437 — MS DOS Extended
- 1252 — Windows
- 866 — DOS Cyrillic
- 1251 — Win Cyrillic
Две последние таблицы также есть в нашем справочнике.
|
Стандат UNICODE
Сейчас идет активный перевод программного обеспечения на двухбайтовую систему
кодировки. Принят международный стандарт, именуемый UNICODE. Этот стандарт имеет
«кодовое пространство» в 216 = 65536
символов, чего вполне достаточно для всех языков мира,
включая полный набор китайских иероглифов (сейчас в китайских компьютерных системах
используется сокращенный набор в примерно 5000 знаков).
Для более удобного перехода ASCII ® UNICODE
разработана специальная кодировка UTF-8 (Unicode Transport Format),
о которой, как и об Уникоде, лучше рассказать отдельно.
|
Картинка
Двухцветную (скажем, черно-белую) картинку можно свести к некоторому «растру»
— прямоугольной решетке и затем рассматривать ее как подмножество черныъ точек
в множестве всех точек этой решетки. А для задания множества можно построить
его характеристический вектор («вытянув» предварительно решетку в линию,
т.е. линейно пронумеровав точки решетки, нумеровать элементы прямого произведения двух
множеств мы уже умеем).
 Например, следуя художнику Малевичу, нарисуем «черный квадрат»
Например, следуя художнику Малевичу, нарисуем «черный квадрат»
6´ 6
на поле 8´ 8 .
Вот этот «Черный квадрат» и ниже его представление в одну строку. Конечно, вместо белых
квадратиков нужно писать нули, а вместо черных — единицы.
Есть и более экономные представления картинок.
00000000 01111110 01111110 01111110 01111110 01111110 01111110 00000000
|
Передача по двоичному каналу связи
В технике связи передачу по каналу связи очень часто рассматривают как последовательность
импульсов, находящихся на двух уровнях (сигнал и нет сигнала ),
и в этом смысле сигнал называют двоичным. Информация, передаваемая по такому каналу связи,
рассматривается как 0-1 последовательность.
Смысл нулей и единиц в этой последовательности может быть очень разнообразным и хитрым.
(это могут быть сжатые тексты и изображения, компьютерные программы, запись звука, шифрограммы).
Некоторые варианты мы в дальнейшем рассмотрим Но чаще всего — это тексты,
о байтовом представлении которых уже говорилось.
|
Результаты случайных испытаний
 В теории вероятностей принято рассматривать случайные последовательности.
Для примера их считают результатами бросания монеты: при падении монета может
упасть на разные стороны, которые традиционно называются Гербом и Решеткой (Решкой). Вот и получается
В теории вероятностей принято рассматривать случайные последовательности.
Для примера их считают результатами бросания монеты: при падении монета может
упасть на разные стороны, которые традиционно называются Гербом и Решеткой (Решкой). Вот и получается
ГГГ РР Г Р ГГ РРРР Г Р Г Р ГГГ Р Г
— те же нули и единицы.
|
Путь в целочисленной решетке
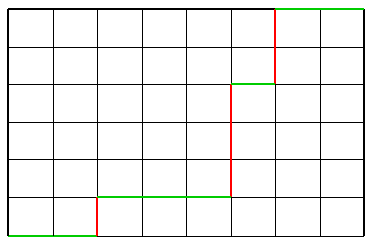 0-1 набор иногда полезно представлять путем на прямоугольной решетке, таким путем, в котором возможны
шаги только вправо или вверх.
0-1 набор иногда полезно представлять путем на прямоугольной решетке, таким путем, в котором возможны
шаги только вправо или вверх.
Вот путь для набора
11 0 111 000 1 00 11 .
По разности координат начала и конца легко судить о числе нулей и единиц в наборе.
|
Штрихкоды
 Нули и единицы, несущие информацию, могут иногда представляться очень своеобразно.
Например, вы уже встречались, вероятно, с полосками на упаковках товаров. Они называются
Нули и единицы, несущие информацию, могут иногда представляться очень своеобразно.
Например, вы уже встречались, вероятно, с полосками на упаковках товаров. Они называются
штрихкодами (barcodes) и предназначены для быстрого считывания информации
специальными устройствами. На фотографии С. Е. Столяра вы видите, как кассир в магазине специальным
сканнером «считывает» штрихкод с упаковки.
Сейчас есть очень много вариантов штрихкодов, специально приспособленных для тех или
иных ситуаций. Рассмотрим только некоторые из них.
Почтовики используют специальные коды для сортировки писем.
Можно сравнить американские и английские коды
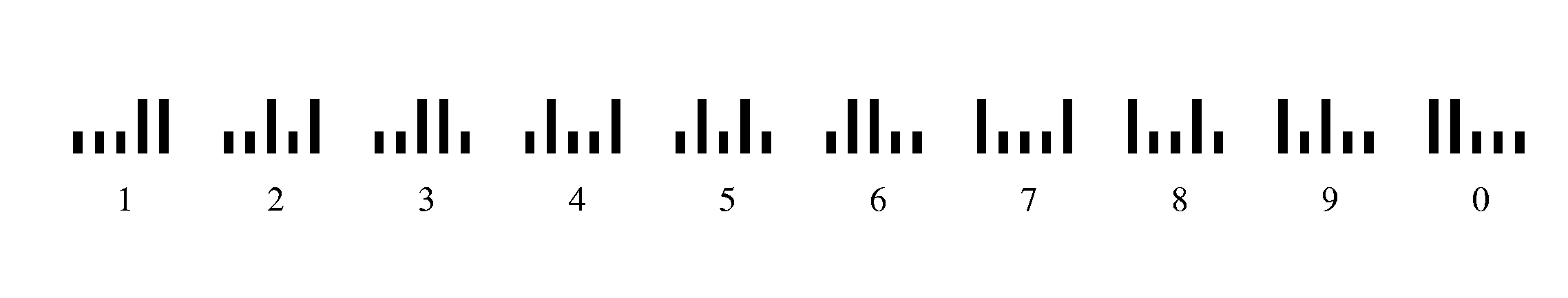
Кодировка почты США позволяет кодировать цифры. Такой код называется «2 из 5» (интересно, почему?).
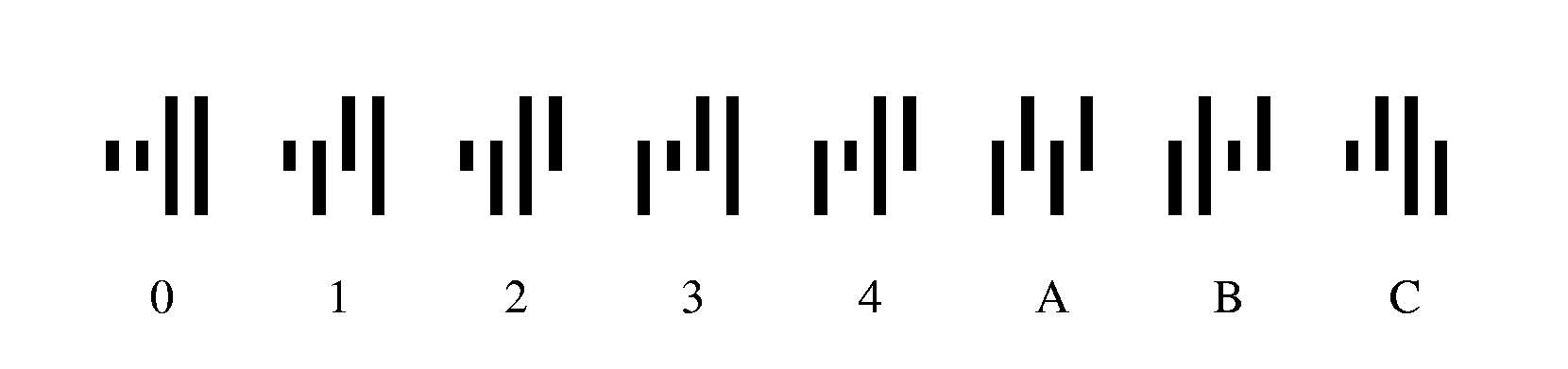
Появившаяся позднее английская кодировка позволяет кодировать цифры и буквы. Попробуйте разобраться,
как эти коды устроены. Например, закодируйте шифр английского почтового отделения
«WE16L5».
|
Представление чисел с плавающей точкой
Мы рассмотрели только самые простые представления 0-1 наборов. Во многих ситуациях набор делится на части,
или поля, каждое из которых трактуется по-своему. Вот важный пример такого рода.
Числа с плавающей точкой представляются в компьютере приблизительно.
Сейчас широко распространен стандарт IEEE, в котором фиксированы две формы числа —
32-битовая и 64-битовая. Мы рассмотрим только первую из них. Итак, число занимает двойное слово,
и составляющие его 32 бита b1,…,b32
разбиты на три поля (это для нас ново: 0-1 набор разбивается
на поля, и только это разбиение нам сейчас важно):
s = b1 — знак числа,
e = b2:9 — порядок числа,
f = b10:32 — дробная часть нормализованной мантиссы,
Таким образом,
x = (-1)s ´ 2e - 127
´ (1.f)
|
Перебор 0-1 наборов
Сейчас мы ответим на три вопроса:
- Сколько элементов в множестве
|Bk| ?
- Как эти элементы перенумеровать ?
- Как эти элементы перебрать ?
Ответы на первые два вопроса мы уже дали раньше:
|Bk| = 2k ,
и каждый набор можно рассматривать как двоичное представление целого числа,
которое и является его номером.
Например, #(0101) = 5.
Как же эти элементы перебрать ?
Очень просто: начать с нулевого набора, которому соответствует
число 0 , а далее прибавлять о единице
(работая прямо с двоичным набором, мы это уже умеем).
| 00000 | 01000 | 10000 | 11000 |
| 00001 | 01001 | 10001 | 11001 |
| 00010 | 01010 | 10010 | 11010 |
| 00011 | 01011 | 10011 | 11011 |
| 00100 | 01100 | 10100 | 11100 |
| 00101 | 01101 | 10101 | 11101 |
| 00110 | 01110 | 10110 | 11110 |
| 00111 | 01111 | 10111 | 11111 |
Однако в некоторых случаях такая форма перебора неудобна из-за того, что при переходе
от одного набора к другому текущий набор сильно изменяется.
Вопрос: нельзя ли осуществить перебор так, чтобы при каждом переходе изменение
было только в одном бите.
Ответ: это возможно.
Мы покажем эту возможность дважды:
Как математики и как программисты.
Как математики:
В первой колонке запишем в половине строк нули, а дальше единицы.
Заполним первую половину наборами длины k-1 ,
а затем зеркально отобразим эти наборы во второй половине.
При этом наборы любой меньшей длины будем перебирать так же.
В таблице показано заполнение еще до зеркального отражения.
А теперь то, что получается
| 0 | 0 | 0 |
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 1 | 0 |
| 1 | 1 | 0 |
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 0 | 0 |
Как программисты:
Запишем перебор наборов по возрастанию и с единичными «мутациями»:
| 0 | 0 | 0 | |
0 | 0 | 0 |
| 0 | 0 | 1 | |
0 | 0 | 1 |
| 0 | 1 | 0 | |
0 | 1 | 1 |
| 0 | 1 | 1 | |
0 | 1 | 0 |
1 | 0 | 0 | |
1 | 1 | 0 |
| 1 | 0 | 1 | |
1 | 1 | 1 |
| 1 | 1 | 0 | |
1 | 0 | 1 |
| 1 | 1 | 1 | |
1 | 0 | 0 |
Видите? Там, где в правой таблице меняется значение бита, в левой появляется 1. (докажите!)
Значит, нужно иметь два рабочих 0-1 набора. В первом моделировать прибавление 1, а во втором,
зная позицию изменения, менять значение бита.
Эта последовательность наборов называется кодом Грея, по имени американского инженера, который
запатентовал такие коды. Они используются при проектировании датчиков угла поворота.
|
Упражнения
- Переведите в двоичную систему числа 34567, 11438, 16 777 351.
- Переведите в 8-ричную и 16-ричную систему число 10101011100010100101010110.
- Выполните все логические операции с наборами
101010010101001010101010 и
000010111101011101011101.
- Закодируйте в ASCII и переведите в двоичную систему текст
Hello, Dolly!
- Нарисуйте черно-белую растровую картинку
16´ 16
и закодируйте ее по строчкам и по столбцам.
- Какой номер имеет набор 0001101110? Сколько наборов такого размера всего?
- Постройте таблицу кодов Грея для
k = 5 .
|
Дополнительная литература

Это действительно классический западный учебник по основным алгоритмам информатики.
Книга дорогая, но очень полезная.
ISBN 5-900916-37-5
|

Книг по комбинаторике очень много, но по программистским вопросам только одна.
Она была издана издательством «Мир» в 1988 году тиражом 45000 экземпляров, так что иногда встречается.
|

В 2008 г. издательство «Вильямс» выпустило несколько тонких
«тетрадок» примерно по 150 стр. Так началась долгожданная публикация
четвертого тома книги Дональда Кнута «Искусство программирования».
Во втором выпуске рассказывается о переборах последовательностей из нулей и единиц
(автор называет их кортежами) и о переборах перестановок, которыми мы будем заниматься
на следующей лекции. Спешите обзаводиться!
ISBN 978-5-8459-1164-3.
|
Экзаменационные вопросы
- Логические значения и операции.
- Логические функции и ДНФ.
- Характеристический вектор множества.
- Кодировка ASCII и ее варианты.
- UNICODE и UTF-8.
- Штрихкоды (по книжке).
- Перебор двоичных наборов и код Грея.
|
|