Оптимизация работы маршрутизатора
Студент 444 группы К.В. Первышев - tpc@mail.ru
Руководитель О.Н. Граничин
Введение
В настоящее время, благодаря росту вычислительных сетей, остро встала проблема качества и быстроты обработки запросов на обслуживание. Типичной является ситуация, когда каким-нибудь сервисом пользуются миллионы человек. Количество запросов, поступающих в систему настолько велико, что даже их переадресация другим узлам локальной сети является критическим процессом, в котором малейшее промедление ведёт к неконтролируемому росту системной очереди и, соответственно, к отказам в обслуживании. В подобных задачах каналы системы могут не знать собственной загруженности. Это является нетипичным для широко использующихся сейчас методов, что и обусловливает необходимость разработки и исследования новых подходов.
Модель системы, в которой для маршрутизации используется крайне малый объём информации, мы позаимствуем из книги О.Н. Граничина и Б.Т. Поляка “Рандомизированные алгоритмы оценивания и оптимизации при почти произвольных помехах” [1] и статьи С.С. Сысоева “Адаптивное управление распределением загрузки в простейшей вычислительной сети” [2].
В тех же работах была предложена идея адаптивного стохастического алгоритма, осуществляющего маршрутизацию в системе с изменяющимися параметрами. Для улучшения характеристик этого алгоритма, зависящего от одного параметра, предлагалось использовать стандартные методы оптимизации. В этой работе мы попытаемся выяснить, насколько необходима подобная оптимизация и насколько она возможна, проведя ряд моделирований.
Модель
Система состоит из двух серверов, способных параллельно обрабатывать N0 и N1 заявок (серверы имеют N0 и N1 каналов), а также маршрутизатора – устройства, принимающего в реальном времени решение, на какой из серверов отправить пришедшую в текущий момент времени заявку. Время обслуживания серверами каждой из заявок считается неизвестным, но одинаково для обоих серверов. Мы будем считать, что промежуток времени между поступающими друг за другом заявками и время обработки заявки – пуассоновские положительные целочисленные случайные величины.
Если заявка направляется на k-ый сервер, и у него один из каналов свободен, то заявка принимается этим сервером на обработку и индикатор Ik устанавливается в единицу. В случае отсутствия свободных каналов запрос перенаправляется на другой сервер. Если у него есть свободный канал, то заявка начинает обрабатываться и индикатор J1-k принимает значение “единица”. Такую ситуацию мы назовём ошибкой маршрутизации, или просто ошибкой. При невозможности обработки заявки ни на одном из серверов происходит отказ в обслуживании и заявка покидает систему.
Задача алгоритма маршрутизации заключается в распределении заявок по серверам таким образом, чтобы количество ошибок было минимальным. При этом алгоритм должен быть устойчивым к изменениям параметров системы (количество каналов на серверах N0 и N1).
Алгоритм
Алгоритм, рассматривавшийся в
работах [1] и [2], заключается в случайном выборе сервера, на который будет
направлена заявка. С вероятностью theta запрос
отправляется на сервер # 0, а с вероятностью (1
- theta) – на сервер
# 1. Для адаптации к параметрам системы theta изменяется
в зависимости от индикаторов I или J
на величину, пропорциональную некоторой малой константе alpha и также,
возможно, theta или (1 - theta). Будем называть этот алгоритм theta-алгоритмом.
Стоит отметить, что “ошибки” необходимы
рассматриваемым в работе стохастическим алгоритмам, поэтому автор предпочитает
под словом “ошибки” понимать лишь статистическую величину, характеризующую
качество работы алгоритма, а для описания ситуации перенаправления заявки с
одного сервера на другой использовать другие термины.
Мы рассмотрим зависимость характеристик работы различных вариантов этого алгоритма в зависимости от постоянной константы alpha.
Эксперименты
Было проведено две серии экспериментов-моделирований. В первой серии количество каналов бралось равным 2 и 4, во второй – на порядок больше, 20 и 40. Мы увидим, что эти две ситуации качественно различны.
Ниже приводятся параметры
моделировавшихся систем. Кроме того, указаны результаты работы “контрольных”
алгоритмов.
[ “косая монетка” – алгоритм с постоянной theta (её значение указывается в скобках)
[ “триггер” – заявки посылаются на один и тот же сервер, пока не произойдёт ошибка. После чего запросы идут на другой сервер, опять же до первой ошибки.
[ “туда-сюда” – заявки посылаются поочерёдно на первый и на второй сервер.
Зависимости процента ошибок от параметра alpha получено для четырех вариаций theta-алгоритма, две из которых можно рассматривать как сумму и как разность двух других. Что интересно, свойства “суммы” и “разности” в определённой степени предсказуемы.
Первая
серия
Параметры системы:
Количество каналов: 2 и 4
Мат. ожидание времени между заявками: 15
Мат. ожидание времени обработки заявки: 80
Время работы системы: 1000000
Всего заявок: 66663.0
Отказов: 7.6 %
"косая монетка" (0.333): 26.9 % ошибок = 17903
"триггер": 31.0 % ошибок
"туда-сюда": 21.2 % ошибок
Вторая
серия
Параметры системы:
Количество каналов: 10 и 20
Мат. ожидание времени между заявками: 15
Мат. ожидание времени обработки заявки: 460
Время работы системы: 1000000
Всего заявок: 66667.0
Отказов: 7.7 %
"косая монетка" (0.333): 22.7 % ошибок = 15140
"триггер": 11.7 % ошибок
"туда-сюда": 21.8 % ошибок
Алгоритм “тета J”
theta := theta
+ alpha * (getIndicatorJ(0)
– getIndicatorJ(1))
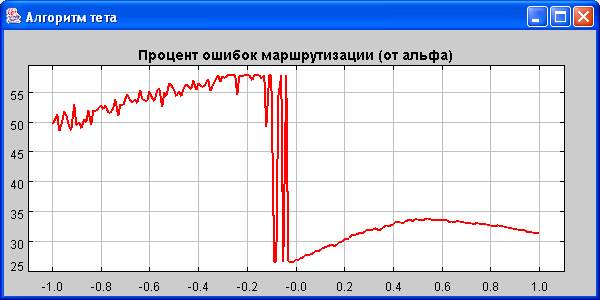
Первая серия

Вторая серия
По графику можно видеть, как theta-алгоритм вырождается при alpha = 0 в “косую монетку”, а при alpha = 1 – в “триггер”. Об этом свидетельствует приблизительное равенство процентов ошибок, отмеченных на графиках, с “контрольными”. Убедиться в совпадении алгоритмов можно непосредственно, подставив соответствующий параметр alpha в формулу. Точного совпадения характеристик в случае “триггера” нет, т.к. в theta-алгоритме theta держится в диапазоне 0.01 . . 0.99.
Алгоритм
“тета I”
theta := theta
+ alpha * (getIndicatorI(0) - getIndicatorI(1))


Алгоритм “тета J – тета I”
theta := theta
+ alpha * (getIndicatorJ(0)
- getIndicatorJ(1))
- alpha * (getIndicatorI(0)
- getIndicatorI(1))


Здесь на правом краю графика можно наблюдать вырождение
алгоритма в “туда-сюда”.
Алгоритм “тета J + тета I”
theta := theta
+ alpha * (getIndicatorJ(0)
- getIndicatorJ(1))
+ alpha * (getIndicatorI(0)
- getIndicatorI(1))


Алгоритм “тета J сглаженный”
theta := theta +
alpha *
* (getIndicatorJ(0) * theta – getIndicatorJ(1)
* (1 – theta))
В алгоритме появились дополнительные множители. Как можно видеть, успехов это не принесло.


Анализ
Результаты эксперимента показывают, что при малом количестве каналов на серверах (2/4) эффективной оказывается нестохастическая стратегия “туда сюда”, при большем же количестве каналов (10/20) выигрывает метод “триггер”. Естественным представляется положить, что параметры системы не меняются на порядок. Таким образом эксперименты не выявили возможностей для применения стохастического тета-алгоритма. Более того, на графиках не видно вогнутости функции ошибок, которая давала бы смысл применению стохастической оптимизации.
Размышления о том, почему же стохастический алгоритм проигрывает, и некоторые дополнительные эксперименты позволяют предположить, что причиной является неограниченность серий, когда заявки направляются на один из серверов. Потребуем, чтобы в тета-алгоритме длины серий были не больше двух.

Первая серия

Вторая серия
Видно, что в первой серии алгоритм значительно выигрывает у всех ранее рассмотренных методов. Можно предположить, что это вызвано тем, что количество каналов на одном из серверов равно двум. Однако во второй серии, в которой количество каналов равно 10 и 20, алгоритм лишь чуть-чуть уступает лучшему из ранее протестированных методов.
Посмотрим более подробно на график во второй серии.

Видно, что оптимальное alpha отнюдь не равно нулю. Для его нахождения нужно применять дополнительные методы.
Заключение
Хотя рассматривавшиеся в ранних работах методы не показали своей эффективности, проделанная работа позволила выявить возможности для развития идеи применения стохастической оптимизации в задаче маршрутизации, использующей минимальный объём информации.
Литература
[1] Граничин О.Н., Поляк Б.Т. Рандомизированные алгоритмы оценивания и оптимизации при почти произвольных помехах. М.: Наука, 2003. 291 с.
[2] Сысоев С. С. Адаптивное управление распределением загрузки в простейшей вычислительной сети.
[3] Сафонов В.О. Введение в Java-технологию. СПб.: Наука, 2002. 187 с.
[4] Гамма Э., Хелм Р., Джонсон Р., Влиссидес Дж. Приёмы объектно-ориентированного проектирования. Паттерны проектирования. СПб.: Питер, 2001. 368 с.