РАЗРАБОТКА ПАРАЛЛЕЛЬНОЙ
АРХИТЕКТУРЫ ДЛЯ РЕАЛИЗАЦИИ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Курсовая работа студента 243-й группы
математико-механического факультета СПбГУ
Косякина Антона Николаевича,
четвёртый семестр 2003/2004 года.
РАЗРАБОТКА ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРЫ ДЛЯ
РЕАЛИЗАЦИИ ИСКУСТВЕННОГО ИНТЕЛЛЕКТА
Как
известно, процесс написания любой программы заключает в себе одну важную и
неотъемлемую часть - проектирование. Для простых программ этот этап достаточно
прост и не занимает большого количества времени, для более сложных - является
одним из главных шагов к решению задачи. Для большинства задач проектирование
заключается в разработке диаграммы классов и объектов, декомпозиции функций, но
для других - приходится разрабатывать ядро программы, её архитектуру, уже на
основе которого будет решаться поставленная перед разработчиком задача.
Именно
эту тему, разработку ядра (архитектуры) программы, я бы и хотел рассмотреть в
своей курсовой работе. Рассматривать данную тему я буду на примере ядра
программы-игрока в виртуальный футбол - RoboCup Soccer Client.
Коротко
о виртуальном футболе
Главной
особенностью данной программы является то, что она основана на технологии
клиент-сервер: при запуске игрок подключается к серверу, устанавливает соединение
и в процессе игры получает некоторую информацию, в ответ на которую генерирует
некоторое действие, которое уже отправляет серверу на исполнение. В промежутке
между получением информации и ответной посылкой действия запускается
искусственный интеллект (далее просто ИИ), который уже и принимает решение.
Однако времени на "размышления" отводится не так много - 100
миллисекунд.
За
всё время существования RoboCup'а было создано огромное количество команд,
исходный код которых доступен в Интернете. Также, при написании собственной
программы-игрока, предлагается использовать уже готовые решения. Однако целью
данной курсовой была разработка альтернативного решения, отличного от уже
существующих. За язык программирования было решено взять чистый C - тоже, как альтернатива
используемому C++ и ООП в подавляющем большинстве существующих программ.
Операционной системой, под которую всё написано, является Linux. 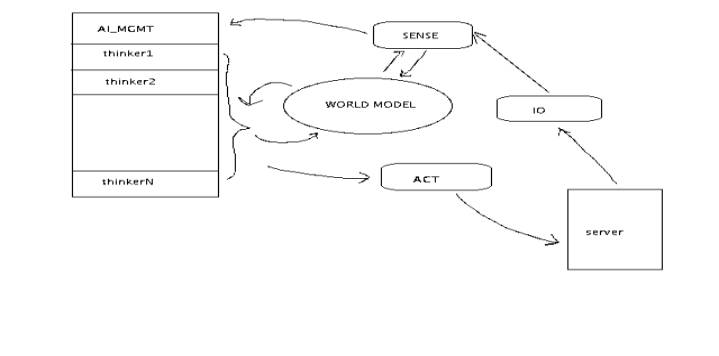
Важной
особенностью разработанной архитектуры является то, что она чётко разделена на
модули. Верхним уровнем декомпозиции являются два основных модуля - ИИ и
транспортный модуль, реализованные как отдельные процессы (см. рисунок).
Транспортный
модуль
Данный
модуль также был подвержен декомпозиции и разбит на несколько более мелких
частей - IO, sense & act. Каждая из этих частей реализована в виде нити
(thread). Было решено использовать такую структуру для того, чтобы максимально
упростить каждый модуль, чётко разграничив "обязанности". Ещё одни
аргументом в пользу распараллеливания стало очевидное преимущество такого
подхода: приём и обработка данных в разных потоках имеют несколько большую
производительность по сравнению с последовательным подходом. Следует заметить,
что в каждый момент времени активен и работает с данными только один поток,
передавая их дальше после завершения своей части работы.
Итак,
в разработанной архитектуре, в транспортном модуле присутствуют 3 потока. За
приём и первичную обработку данных отвечает IO. Было решено вынести его в
отдельный поток в связи с тем, что со временем протокол передачи данных между
клиентом и сервером может меняться. Поэтому любые изменения придётся внести в
основном только в код самого IO: его основной задачей является приём данных и
переработка их в заранее определённый внутренний язык, который "понимают"
все остальные модули.
После
первичной обработки, данные передаются потоку sense. Он отвечает за дальнейшую
обработку данных, извлечение из них полезной информации и запоминание её в
общей базе данных - world model, модели мира. Также, получив некоторый набор данных,
он (sense) шлёт уведомление ИИ о получении новой информации.
Последним в
данной тройке является act, поток, отвечающий за передачу команд от ИИ на
сервер.
World Model
Являясь
общей базой данных для всей программы, модель мира представляет собой область
разделяемой между всеми процессами памяти, имеющей определённую структуру.
Каждому потоку, которому разрешено взаимодействовать с ней, доступны функции
записи и чтения информации из неё.
Организация ИИ
Отличительной
особенностью данного модуля является тот факт, что некоторая его часть написана
на C++ - для обеспечения удобства реализации ИИ. Как и в прошлом случае, данный
модуль тоже разделён на несколько потоков. Главным из них является ai_mgmt -
менеджер ИИ-потоков. В дополнение к нему имеется пул потоков (thinker'ы),
умеющих выполнять некоторые действия.
По
приходу уведомления от sense, ai_mgmt стартует все доступные thinker'ы,
одновременно включая таймер. После его (таймера) срабатывания - останавливает
работу thinker'ов и получает от них результат работы. Далее он выбирает
наилучший из них и передаёт дальше - потоку act.
Немного о
реализации
При
реализации данной архитектуры использовались все доступные стандартом POSIX
низкоуровневые средства синхронизации процессов и обмена данными между ними -
очереди сообщений, семафоры, разделяемая память. Для создания двух процессов
использовалась стандартная функция fork(), а работа с потоками основывалась на
библиотеке POSIX Threads.
Заключение
В
заключении хочу сказать, что результат превзошёл ожидания: реализация описанной
архитектуры по скорости обработки данных обходит архитектуру команды чемпионов
мира - UvA Trilearn. Сравнение производительности осуществлялось таким образом:
внутри кода каждой из архитектур, сразу же после получения данных от сервера,
был вставлен код, запоминающий текущее время (с точностью до десятков
миллисекунд). Аналогичный код вставлялся в месте прихода данных к ИИ. В
результате многократных измерений выяснилось, что полный путь принятых данных
от сервера и до ИИ в архитектуре Trilearn занимал в среднем 20-30 миллисекунд,
а в описанной выше - только 10мс.